基本概念 参数推导 模型设定 假设条件 假设检验 stata代码实现 python代码实现
在统计学中,线性回归(英语:Linear Regression)是利用称为线性回归方程的最小二乘函数对一个或多个解释变量和被解释变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个解释变量的情况称为一元回归,大于一个解释变量情况的叫做多元回归(multivariable linear regression)。[1]
注:在经济学中,自变量也被称为解释变量,因变量也称为被解释变量 。同时存在多个自变量的情况下,还会将自变量分为核心解释变量和控制变量,但需要注意的一点是,这种区分是人为区分的,在估计参数时,统一将其当作自变量处理 。在本文当中,会统一使用解释变量和被解释变量的称呼,需注意。
举个例子:想象你是一位房产中介,你发现房子面积越大,价格似乎越高。你想量化这种关系,这就是线性回归要解决的问题,分析解释变量对被解释变量的变化的可以解释程度。
\begin{align}
Y = \beta_0 + \beta_1X + \varepsilon
\end{align}
其中:
Y Y Y X X X β 0 \beta_0 β 0 β 1 \beta_1 β 1 ε \varepsilon ε
注:其实从这个地方也能看得出来,线性回归本身描述是真实值Y Y Y Y Y Y X i X_i X i Y i Y_i Y i E ( Y i ∣ X i ) = Y E(Y_i | X_i)=Y E ( Y i ∣ X i ) = Y
若你认为价格不仅可以被面积影响,还有其他因素,那么可以通过添加其他解释变量来提高回归模型的预测效果,如当地的经济发展水平,地区人口密度等,那你的模型就可以表示为:
\begin{align}
Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \beta_3X_3 + \varepsilon \end{align}
其中:
Y Y Y X 1 X_1 X 1 X 2 X_2 X 2 X 3 X_3 X 3 β 0 \beta_0 β 0 β i \beta_i β i X i X_i X i ε \varepsilon ε
其中( 1 ) (1) ( 1 ) ( 2 ) (2) ( 2 )
更一般的,线性回归被表示为:
\begin{align}
Y=\beta_0+\beta_1X_1+\beta_2X_2+...+\beta_nX_n+\varepsilon \end{align}
若令:
Y = [ y 1 y 2 ⋮ y n ] , X = [ 1 x 11 x 12 ⋯ x 1 n 1 x 21 x 22 ⋯ x 2 n ⋮ ⋮ ⋮ ⋱ ⋮ 1 x n 1 x n 2 ⋯ x n n ] , β = [ β 0 β 1 ⋮ β n ] \mathbf
Y =
\begin{bmatrix}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{bmatrix},
X =
\begin{bmatrix}
1 & x_{11} & x_{12} & \cdots & x_{1n} \\
1 & x_{21} & x_{22} & \cdots & x_{2n} \\
\vdots &\vdots & \vdots & \ddots & \vdots \\
1 & x_{n1} & x_{n2} & \cdots & x_{nn}
\end{bmatrix},
\beta =
\begin{bmatrix}
\beta_0 \\
\beta_1 \\
% \beta_2 \\
\vdots \\
\beta_n
\end{bmatrix}
Y = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ y 1 y 2 ⋮ y n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ , X = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ 1 1 ⋮ 1 x 1 1 x 2 1 ⋮ x n 1 x 1 2 x 2 2 ⋮ x n 2 ⋯ ⋯ ⋱ ⋯ x 1 n x 2 n ⋮ x n n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ , β = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ β 0 β 1 ⋮ β n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
则线性回归就可以被简洁的表示为:
\begin{align} \bf Y=X\beta+\varepsilon \end{align}
不少人会对线性回归有所疑惑,模型数学表达式知道了,那么如何推导出参数呢?其实参数的推导是来自于数据本身的,也就是说,参数是根据数据所决定的,而不是模型所决定的。更通俗点就是由Y 、 X Y、X Y 、 X
\begin{align} Y_i=\beta_0+\beta_1X_i \end{align}
估计模型为:
\begin{align} \hat{Y_i}=\hat{\beta_0}+\hat{\beta_1}X_i+\varepsilon_i \end{align}
其中ε \varepsilon ε X X X Y Y Y Y i ^ \hat{Y_i} Y i ^ a ^ \hat{\phantom{a}} a ^
\begin{align} \varepsilon_i = Y_i-\hat{Y_i}\end{align}
拟合的目标就是想要让,预测值Y i ^ \hat{Y_i} Y i ^ Y i Y_i Y i
\begin{align} \sum_{i=1}^n \varepsilon_i^2 = \sum_{i=1}^n(Y_i-\hat{Y_i})^2 \end{align}
得到最小二乘目标函数:
\begin{align} \min \sum_{i=1}^n (Y_i - \beta_0 - \beta_1X_i)^2 = \min \sum_{i=1}^n (Y*i - \hat{Y_i})^2 = min\sum_{i=1}^n \varepsilon_i^2 \end{align}
对β 0 , β 1 \beta_0, \beta_1 β 0 , β 1
\begin{align}
\frac{\partial f}{\partial \beta_0} &= -2\sum_{i=1}^n (Y_i - \beta_0 - \beta_1X)=0 \\
\frac{\partial f}{\partial \beta_1} &= -2 \sum_{i=1}^n X_i(Y_i - \beta_0 - \beta_1X_i)=0
\end{align}
对其进行求解,就可以得到下列参数方程。
一元线性回归参数方程:
\begin{align}
&\hat{\beta}_1 = \frac{\sum_{i=1}^n (X_i - \bar{X})(Y_i - \bar{Y})}{\sum_{i=1}^n (X_i - \bar{X})^2}\\
&\hat{\beta}_0 = \bar{Y} - \hat{\beta}_1\bar{X}
\end{align}
其中 X ˉ \bar{X} X ˉ Y ˉ \bar{Y} Y ˉ
线性回归模型假定,Y Y Y X X X ( 3 ) (3) ( 3 )
\begin{align} Y=\beta_0+\beta_1X_1+ \beta_2X_2^2 + \varepsilon \end{align}
该模型仍然是线性关系,但若形式为:
\begin{align} Y=\beta_0+\beta_1X_1+ \beta_2^2X_2 + \varepsilon \end{align}
则该模型不再满足线性关系,因为参数β 2 \beta_2 β 2
\begin{align}lnY=\beta_0+\beta_1lnX_1+ \beta_2lnX_2 + \varepsilon \end{align}
仍然是满足线性关系假定的,这种模型也被称为双对数模型,在实践中也经常被使用,因为该模型表达了解释变量X X X Y Y Y
\begin{align}Y=AK^\alpha L^\beta \end{align}
对两边取对数,可以得到:
\begin{align}lnY=lnA+\alpha lnK+\beta lnL+ \varepsilon \end{align}
通过对数变换,就可以将非线性模型转换为线性模型。
该假定义为:E ( ε ) = 0 E(\varepsilon) = 0 E ( ε ) = 0 ( 8 ) (8) ( 8 ) β 0 = 2 ∑ i = 1 n ( Y i − β 0 − β 1 X ) = 0 \beta_0 = 2\sum_{i=1}^n (Y_i - \beta_0 - \beta_1X)=0 β 0 = 2 ∑ i = 1 n ( Y i − β 0 − β 1 X ) = 0 ε ˉ = ∑ i n ε n \bar\varepsilon=\frac{\sum_{i}^n \varepsilon}{n} ε ˉ = n ∑ i n ε ε ˉ = 0 \bar\varepsilon=0 ε ˉ = 0 E ( Y i ∣ X i ) = Y E(Y_i | X_i)=Y E ( Y i ∣ X i ) = Y E ( ε ∣ X i ) = 0 E(\varepsilon | X_i)=0 E ( ε ∣ X i ) = 0 E ( ε ) = E ( E ( ε ∣ X i ) ) = E ( 0 ) = 0 E(\varepsilon)=E(E(\varepsilon | X_i))=E(0)=0 E ( ε ) = E ( E ( ε ∣ X i ) ) = E ( 0 ) = 0
1 2 3 4 5 6 7 8 sysuse auto, clear reg price weight predict y_hat, xb gen resid = price - y_hat sum resid, detail di %9.2f r (sum ) 0.00
可以从上面的回归结果发现,残差和正好为 0,这里保留 2 位小数是因为stata 在计算过程中,可能会因为精度的不同,结构会有些许误差。
该假定假设当模型存在多个解释变量时即当模型是多元线性回归的时候,这些解释变量之间不存在完全的线性关系。这是因为当模型的多个变量存在完全的线性关系时,模型参数将无法估计。假定模型为:
\begin{align}Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \varepsilon \end{align}$$$$\begin{align}X_2 = \alpha X_1 + \varepsilon \end{align}
则可以发现,X 2 X_2 X 2 X 1 X_1 X 1 ( 15 ) (15) ( 1 5 )
\begin{align}
Y &= \alpha_0 + \beta_1X_1 + \beta_2(\alpha X_1 + \varepsilon) + \varepsilon \\
&= \alpha_0 + (\beta_1 + \alpha\beta_2)X_1 + (\beta_2 + 1)\varepsilon \\
&= \alpha_0 + \beta X_1 + \varphi
\end{align}
其中β = β 1 + α β 2 \beta = \beta_1 + \alpha\beta_2 β = β 1 + α β 2 φ = ( β 2 + 1 ) ε \varphi = (\beta_2 + 1)\varepsilon φ = ( β 2 + 1 ) ε X 2 X_2 X 2 X 2 X_2 X 2 Y Y Y X 1 X_1 X 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 sysuse auto, clear # 载入数据rename weight x1 # 重命名变量为x1gen x2 = 1 + 2 * x1 # 生成变量x2,x2 = 1 + 2 * x1reg price x2 x1note : x1 omitted because of collinearity. Source | SS df MS Number of obs = 74 -------------+---------------------------------- F (1, 72) = 29.42 Model | 184233937 1 184233937 Prob > F = 0.0000 Residual | 450831459 72 6261548.04 R-squared = 0.2901 -------------+---------------------------------- Adj R-squared = 0.2802 Total | 635065396 73 8699525.97 Root MSE = 2502.3 ------------------------------------------------------------------------------ price | Coefficient Std. err . t P>|t| [95% conf . interval] -------------+---------------------------------------------------------------- x2 | 1.022031 .1884171 5.42 0.000 .6464287 1.397634 x1 | 0 (omitted) _cons | -7.729385 1174.612 -0.01 0.995 -2349.276 2333.817 ------------------------------------------------------------------------------
可以看到,X 2 = 1 + 2 ∗ X 1 X_2 =1 + 2*X_1 X 2 = 1 + 2 ∗ X 1 X 1 X_1 X 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import numpy as npfrom statsmodels.formula.api import olsimport pandas as pdfrom sklearn.datasets import load_irisX, y = load_iris(return_X_y=True ) data = pd.concat([pd.DataFrame(X), pd.DataFrame(y)], axis=1 ) data.columns = ["x1" , "x2" , "x3" , "x4" , "y" ] data["x1" ] = 1 + 2 * data["x2" ] model = ols('y ~ x1 + x2 + x3 + x4 ' , data).fit() print (model.summary()) OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.929 Model: OLS Adj. R-squared: 0.927 Method: Least Squares F-statistic: 632.8 Date: Thu, 24 Jul 2025 Prob (F-statistic): 1.98e-83 Time: 11 :19 :36 Log-Likelihood: 15.513 No. Observations: 150 AIC: -23.03 Df Residuals: 146 BIC: -10.98 Df Model: 3 Covariance Type : nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975 ] ------------------------------------------------------------------------------ Intercept 0.0200 0.162 0.123 0.902 -0.300 0.340 x1 -0.0412 0.015 -2.701 0.008 -0.071 -0.011 x2 -0.0306 0.074 -0.414 0.679 -0.176 0.115 x3 0.1493 0.040 3.743 0.000 0.070 0.228 x4 0.6715 0.090 7.488 0.000 0.494 0.849 ============================================================================== Omnibus: 0.576 Durbin-Watson: 1.138 Prob(Omnibus): 0.750 Jarque-Bera (JB): 0.299 Skew: 0.084 Prob(JB): 0.861 Kurtosis: 3.139 Cond. No. 1.74e+16 ============================================================================== Notes: [1 ] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2 ] The smallest eigenvalue is 3.82e-29 . This might indicate that there are strong multicollinearity problems or that the design matrix is singular.
可以发现在上面,也报出了多重共线性的错误。
该假设说明了误差项的方差是是一个常数,即V a r ( ε ∣ X ) = σ 2 Var(\varepsilon|X) = \sigma^2 V a r ( ε ∣ X ) = σ 2
该假设说明了误差项之间不存在自相关关系,即C o v ( ε i ∣ ε j ) = 0 , ( i ≠ j ) Cov(\varepsilon_i | \varepsilon_j) = 0, (i \neq j) C o v ( ε i ∣ ε j ) = 0 , ( i = j )
该假设是说,解释变量与误差项不存在相关关系,即C o v ( X i , ε i ) = 0 Cov(X_i,\varepsilon_i)=0 C o v ( X i , ε i ) = 0 E ( ε i ∣ X ) = 0 E(\varepsilon_i | X)=0 E ( ε i ∣ X ) = 0
该假设是说,误差项是服从正态分布的,即ε i ∼ N ( 0 , σ 2 ) \varepsilon_i \sim N(0, \sigma^2) ε i ∼ N ( 0 , σ 2 ) σ 2 \sigma^2 σ 2
为了文章的简洁性,各种假设的检验方法,我将在后面的文章中详细介绍。
之所以线性回归会使用最小二乘法( O L S ) (OLS) ( O L S ) 最优线性无偏估计(BLUE) ,也称高斯-马尔可夫定理。
线性性O L S OLS O L S Y Y Y ( 9 ) (9) ( 9 ) β i \beta_i β i Y Y Y
\begin{align}
&\hat{\beta}_1 = \frac{\sum_{i=1}^n (X_i - \bar{X})(Y_i - \bar{Y})}{\sum_{i=1}^n (X_i - \bar{X})^2}\\
&\hat{\beta}_0 = \bar{Y} - \hat{\beta}_1\bar{X}
\end{align}
无偏性β ^ i \hat\beta_i β ^ i β i \beta_i β i E ( β ^ i ) = β i E(\hat\beta_i) = \beta_i E ( β ^ i ) = β i
一致性
符号规定:
n n n k k k y i y_i y i y ^ i \hat y_i y ^ i y ˉ \bar y y ˉ
定义:
\begin{align} RSS = \sum_{i=1}^n(y_i - \hat y_i)^2\end{align}
含义:残差平方和,他表示了模型未能解释的部分,即估计的(\hat y_i) 与真实值(y_i) 之间的距离。d f R S S = n − k − 1 df_{RSS} = n-k-1 d f R S S = n − k − 1
E S S ESS E S S 定义:
\begin{align} ESS = \sum_{i=1}^n(\hat y_i - \bar y)^2\end{align}
含义:回归平方和,表示模型解释的部分。d f E S S = k df_{ESS} = k d f E S S = k
T S S TSS T S S 定义:
\begin{align} TSS &= \sum_{i=1}^n(y_i - \bar y)^2 \\
&= RSS + ESS
\end{align}
含义:总平方和,表示数据集的方差。d f T S S = d f E S S + d f R S S = n − 1 df_{TSS} = df_{ESS} + df_{RSS} = n-1 d f T S S = d f E S S + d f R S S = n − 1
R 2 R^2 R 2 定义:
\begin{align}
R^2 &= 1 - \frac{\sum_{i=1}^n(y_i - \hat{y_i})^2}{\sum_{i=1}^n(y_i - \bar{y})^2} \\
&= 1 - \frac{RSS}{TSS} \\
&= \frac{ESS}{TSS}
\end{align}
其中,R 2 R^2 R 2 R 2 R^2 R 2 [ 0 , 1 ] [0,1] [ 0 , 1 ]
注:R 2 R^2 R 2 R 2 R^2 R 2
R ˉ 2 \bar R^2 R ˉ 2 定义:
R ˉ 2 = 1 − E S S / ( n − k − 1 ) T S S / ( n − 1 ) = 1 − M S E T S S / ( n − 1 ) = 1 − ( 1 − R 2 ) ( n − 1 ) n − k − 1 \begin{aligned}
\bar R^2 &= 1 - \frac{ESS/(n-k-1)}{TSS/(n-1)} \\
&= 1 - \frac{MSE}{TSS/(n-1)} \\
&= 1 - \frac{(1-R^2)(n-1)}{n-k-1}
\end{aligned}
R ˉ 2 = 1 − T S S / ( n − 1 ) E S S / ( n − k − 1 ) = 1 − T S S / ( n − 1 ) M S E = 1 − n − k − 1 ( 1 − R 2 ) ( n − 1 )
R ˉ 2 \bar R^2 R ˉ 2 R 2 R^2 R 2 R 2 R^2 R 2 R 2 R^2 R 2 假设3 提到,模型的解释变量之间不能严重的存在多重共线性,因此,R ˉ 2 \bar R^2 R ˉ 2 R 2 R^2 R 2 R ˉ 2 \bar R^2 R ˉ 2 R 2 R^2 R 2 R ˉ 2 \bar R^2 R ˉ 2 R ˉ 2 \bar R^2 R ˉ 2
注:选择使用哪个系数进行判断,需要根据实际情况选择。
这里的假设检验并不是对各种假设条件的检验,而是对估计参数的统计检验,也就是通过统计学的方法来判断我们估计的参数是否有效,主要包括了 t t t F F F
设原假设为:
H 0 : β i = 0 H_0: \beta_i = 0
H 0 : β i = 0
备择假设(双尾检验)为:
H 1 : β i ≠ 0 H_1: \beta_i \neq 0
H 1 : β i = 0
注:若理论支持方向性,可改用单尾检验(如H 1 : β i > 0 H_1: \beta_i > 0 H 1 : β i > 0 H 1 : β i < 0 H_1: \beta_i < 0 H 1 : β i < 0
即原假设假设解释变量对被解释变量不具备影响能力。备择假设则认为解释变量对被解释变量有影响。
\begin{align}t(n-k-1) = \frac{\hat{\beta_i} - \beta_i}{SE(\hat{\beta_i})}\end{align}
其中,n − k − 1 n-k-1 n − k − 1 n 、 k n、k n 、 k β i ^ \hat{\beta_i} β i ^ β i \beta_i β i S E ( β i ^ ) SE(\hat{\beta_i}) S E ( β i ^ ) β i = 0 \beta_i = 0 β i = 0
\begin{align}t(n-k-1) = \frac{\hat{\beta_i} - 0}{SE(\hat{\beta_i})}\end{align}
得到 t 统计量后,我们首先要查表确定在这个自由度下的t α / 2 ( n − k − 1 ) t_{\alpha/2}{(n-k-1)} t α / 2 ( n − k − 1 ) α \alpha α t α / 2 t_{\alpha/2} t α / 2 | t | > t α / 2 |t| > t_{\alpha/2} | t | > t α / 2 p p p t t t p p p p < α p< \alpha p < α
1 2 3 4 5 6 . display invttail (20, 0.025) #其中20为自由度,0.025为α, 得到的是临界值 2.0859634 . display 2 * ttail (20, abs (4)) #其中 20 为自由度,4为 t 统计量,(若是双尾检验则需要*2,若是单尾则不需要),得到p值 .00070352
这一部分可以看代码实现 部分,会没那么抽象。
F 检验主要用于检验多个解释变量之间是否同时满足某个条件,例如模型设为:
Y = β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β n X n + ε Y = \beta_0 + \beta_1X_1 + \beta_2X_2 +\dots+ \beta_nX_n + \varepsilon
Y = β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β n X n + ε
则 F 检验的原假设为:
H 0 : β 1 = β 2 = ⋯ = β n = 0 H_0: \beta_1 = \beta_2 = \dots =\beta_n = 0
H 0 : β 1 = β 2 = ⋯ = β n = 0
备择假设为:
H 1 : 至少一个 β i ≠ 0 , { i = 1 , 2 , … , n } H_1: 至少一个\beta_i \neq 0, \{i=1,2,\dots,n\}
H 1 : 至 少 一 个 β i = 0 , { i = 1 , 2 , … , n }
F 检验的统计量计算公式为:
\begin{align} F(k-1, n-k) &&=\frac{ESS/(k-1)}{RSS/(n-k)} \end{align}
其中:
R S S RSS R S S E S S ESS E S S k k k n n n
F 检验实际上是在检验整个模型的有效性,若解释变量的系数均为 0,那么这个模型也就无效了,若起码有一个系数不为 0,那么这个模型仍然是有效的。这是一个很关键的点,
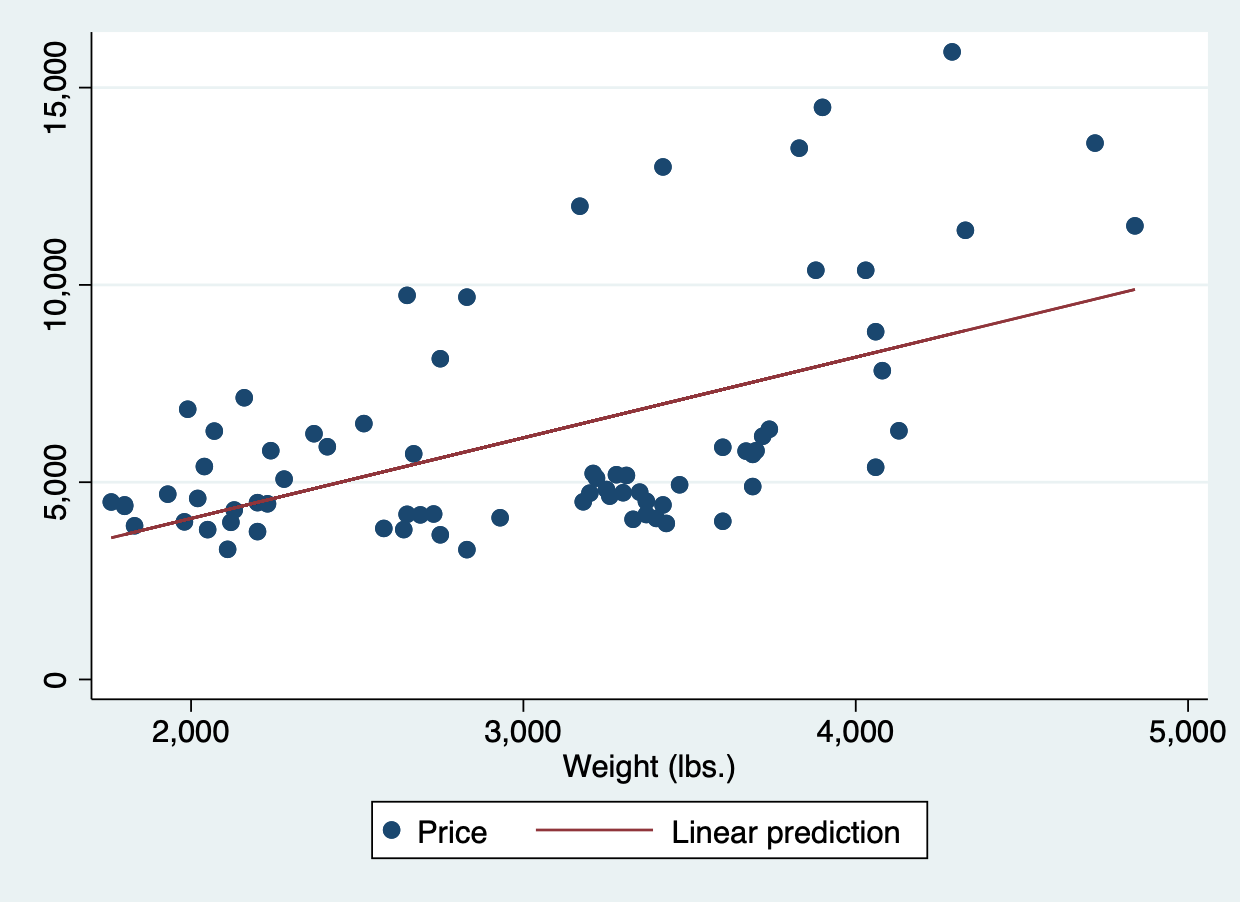
我们使用 stata 自带的 auto 数据进行一次一元的线性回归分析,以 price为被解释变量,weight 为解释变量,设模型为如下形式:
Y = β 0 + β 1 X + ε Y = \beta_0 + \beta_1X + \varepsilon
Y = β 0 + β 1 X + ε
其中Y Y Y X X X ε \varepsilon ε
1 2 3 4 5 . sysuse auto, clear (1978 automobile data) . end of do -file
这一步操作主要是导入数据 stata 自带的 auto 数据集,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 . rename price Y . rename weight X . reg Y X Source | SS df MS Number of obs = 74 -------------+---------------------------------- F (1, 72) = 29.42 Model | 184233937 1 184233937 Prob > F = 0.0000 Residual | 450831459 72 6261548.04 R-squared = 0.2901 -------------+---------------------------------- Adj R-squared = 0.2802 Total | 635065396 73 8699525.97 Root MSE = 2502.3 ------------------------------------------------------------------------------ Y | Coefficient Std. err . t P>|t| [95% conf . interval] -------------+---------------------------------------------------------------- X | 2.044063 .3768341 5.42 0.000 1.292857 2.795268 _cons | -6.707353 1174.43 -0.01 0.995 -2347.89 2334.475 ------------------------------------------------------------------------------ . end of do -file
结果如上所示,现在我们来解析一下这个结果,首先看左上方的结果,如下所示,其中S o u r c e Source S o u r c e S S SS S S d f df d f 表示均方差。第二行第三行分别表示模型和残差 表示均方差。第二行第三行分别表示模型和残差 表 示 均 方 差 。 第 二 行 第 三 行 分 别 表 示 模 型 和 残 差 、 、 、 、 、 、 ,以及总 ,以及总 , 以 及 总 、 、 、 、 、 、
1 2 3 4 5 6 Source | SS df MS -------------+---------------------------------- Model | 184233937 1 184233937 Residual | 450831459 72 6261548.04 -------------+---------------------------------- Total | 635065396 73 8699525.97
然后再看右上方的结果,如下所示,其中F ( 1 , 72 ) = 29.42 F(1, 72)=29.42 F ( 1 , 7 2 ) = 2 9 . 4 2 ( 1 , 72 ) (1, 72) ( 1 , 7 2 ) F F F 29.42 29.42 2 9 . 4 2 P > F P>F P > F F F F p p p R 2 R^2 R 2 R 2 R^2 R 2
1 2 3 4 5 6 Number of obs = 74 F (1, 72) = 29.42Prob > F = 0.0000R-squared = 0.2901 Adj R-squared = 0.2802 Root MSE = 2502.3
最后再来看下方的参数估计表,如下方所示,其中第一行为标头,分别表示被解释变量Y Y Y β \beta β β \beta β t t t β \beta β P > ∣ t ∣ P>|t| P > ∣ t ∣ t t t p p p X X X
1 2 3 4 5 6 ------------------------------------------------------------------------------ Y | Coefficient Std. err . t P>|t| [95% conf . interval] -------------+---------------------------------------------------------------- X | 2.044063 .3768341 5.42 0.000 1.292857 2.795268 _cons | -6.707353 1174.43 -0.01 0.995 -2347.89 2334.475 ------------------------------------------------------------------------------
于是通过上面的分析,我们可以写出如下的估计线性方程:
\begin{align} Y = -6.707353 + 2.044063X + \varepsilon \end{align}
我们通过使用 sklearn 的鸾尾花数据集进行分析,得到下面的结果,解读方法和stata 的差不多,只是在这儿,常数是Intercept,coef 是系数,std err 是标准误差,Prob (F-statistic)是 F 检验的p值。更多的介绍将在后面分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import numpy as npfrom statsmodels.formula.api import olsimport pandas as pdfrom sklearn.datasets import load_irisX, y = load_iris(return_X_y=True ) data = pd.concat([pd.DataFrame(X), pd.DataFrame(y)], axis=1 ) data.columns = ["x1" , "x2" , "x3" , "x4" , "y" ] model = ols('y ~ x1 + x2 + x3 + x4 ' , data).fit() print (model.summary()) OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.930 Model: OLS Adj. R-squared: 0.928 Method: Least Squares F-statistic: 484.5 Date: Sat, 26 Jul 2025 Prob (F-statistic): 8.46e-83 Time: 14 :39 :31 Log-Likelihood: 17.437 No. Observations: 150 AIC: -24.87 Df Residuals: 145 BIC: -9.821 Df Model: 4 Covariance Type : nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975 ] ------------------------------------------------------------------------------ Intercept 0.1865 0.205 0.910 0.364 -0.218 0.591 x1 -0.1119 0.058 -1.941 0.054 -0.226 0.002 x2 -0.0401 0.060 -0.671 0.503 -0.158 0.078 x3 0.2286 0.057 4.022 0.000 0.116 0.341 x4 0.6093 0.094 6.450 0.000 0.423 0.796 ============================================================================== Omnibus: 0.374 Durbin-Watson: 1.077 Prob(Omnibus): 0.829 Jarque-Bera (JB): 0.141 Skew: -0.051 Prob(JB): 0.932 Kurtosis: 3.110 Cond. No. 91.9 ============================================================================== Notes: [1 ] Standard Errors assume that the covariance matrix of the errors is correctly specified.
参考文献:维基百科编者. 線性回歸[G/OL]. 维基百科, 2025(20250705)[2025-07-05].